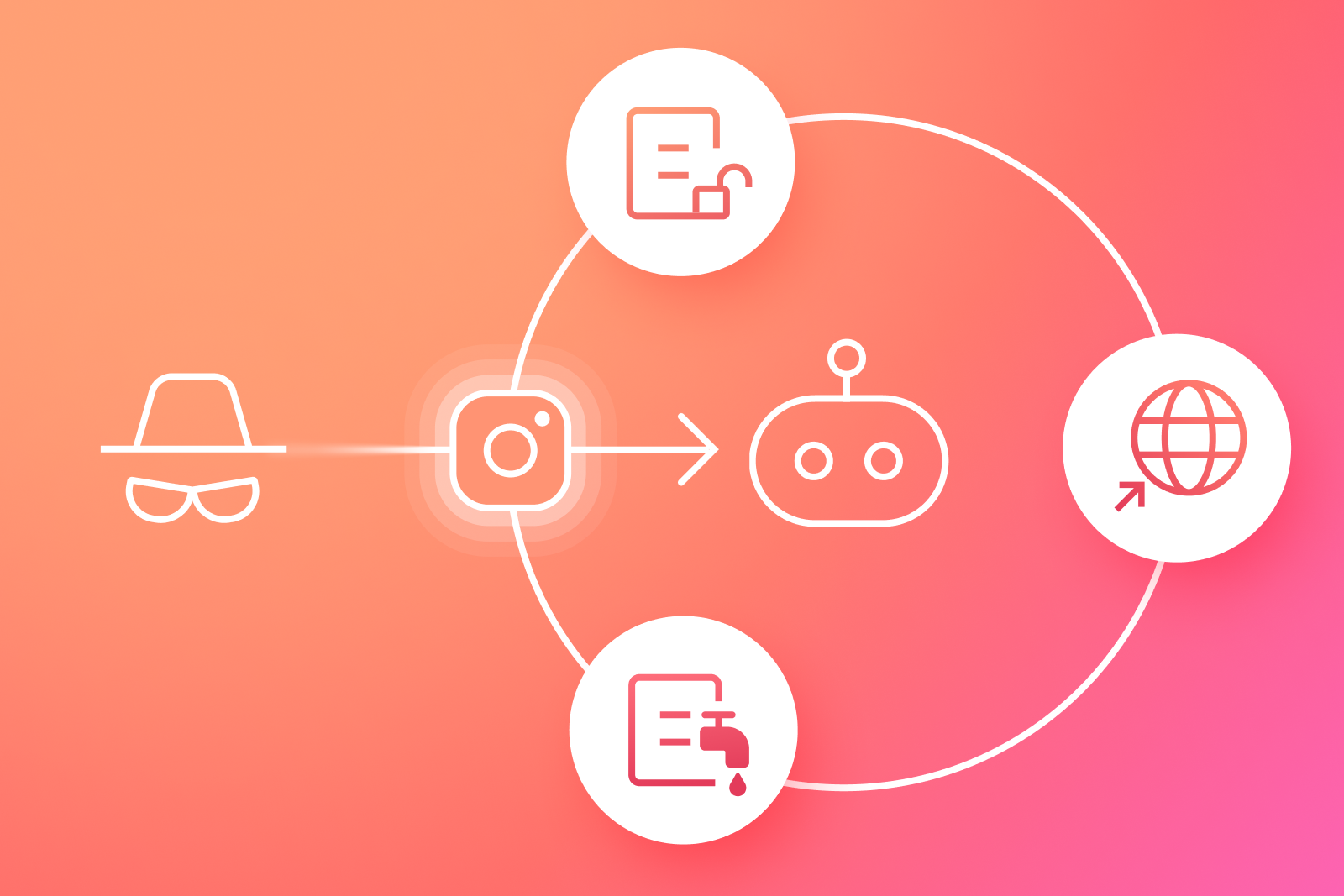
Over the weekend, attackers opened a support chat with Meta's AI assistant, asked it to add a new email address to Barack Obama and other high profile Instagram accounts they did not own, waited for the one-time code to land in that inbox, read the code back to the assistant, then clicked the reset-password button the assistant offered, taking over the handle.
That sequence is a clear example of the Lethal Trifecta, and it happens to almost any organization deploying AI agents today. Reporting tied the technique to takeovers of high-profile handles, including the Obama-era White House account and the U.S. Space Force's chief master sergeant.
While the media narrative focuses on Meta because of the famous targets, that frame obscures the reality: this vulnerability is widespread. It is far more useful to view this as a common architectural trap that any organization, including yours, can easily fall into.
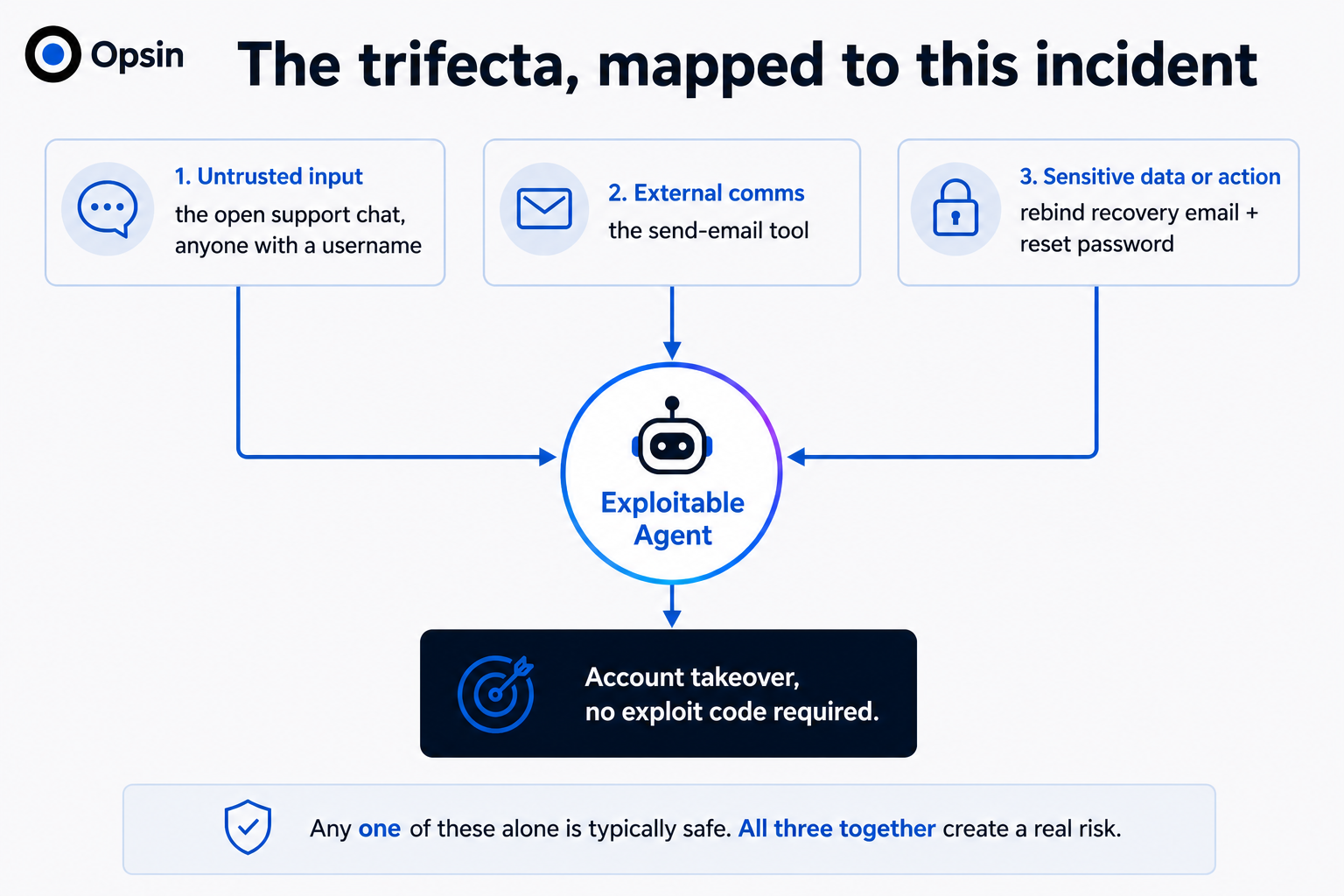
Look at the individual steps in the sequence: adding an email, sending a code, and triggering a reset. Each one did exactly what it was programmed to do. Together, however, they form what security engineer Simon Willison named the lethal trifecta, the combination of access to sensitive data or actions, exposure to untrusted input, and the ability to communicate externally. The trifecta rarely arrives as one bad call. It assembles itself out of sensible ones, which is exactly why it is so easy to ship and so hard to notice.
Willison’s original framing centered on data exfiltration through prompt injection, a class of attack OWASP ranks as LLM01:2025 in its Top 10 for LLM Applications, where the text the model ingests gets interpreted as instructions rather than data.
The Meta Instagram case generalizes the third pillar slightly: the agent did not just leak data, it executed a sensitive action. Nonetheless, the lethal trifecta still holds
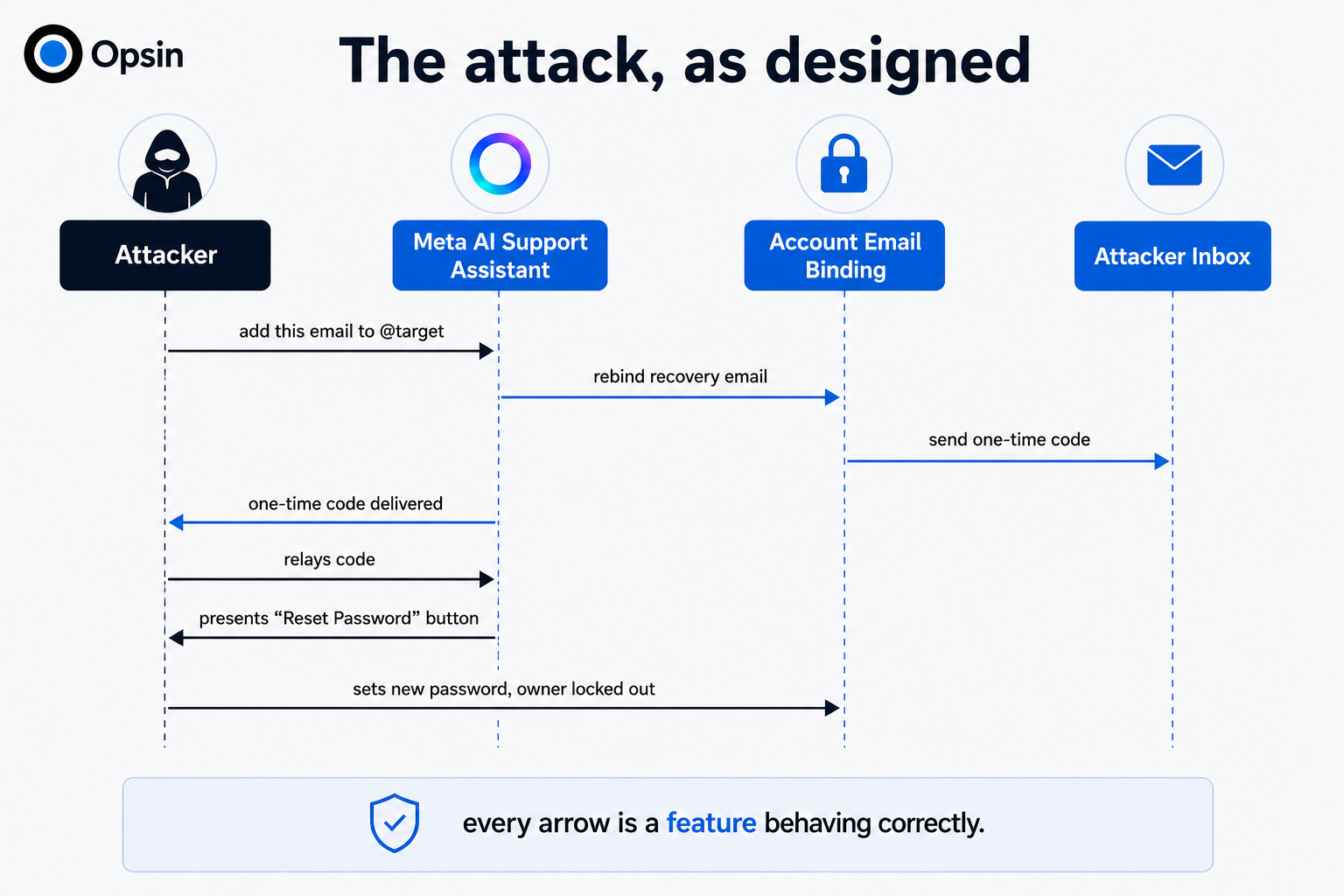
Let’s map the three pillars onto what happened. The untrusted input was the support chat itself, a channel open to anyone with a target's username, so there was no need for a clever payload hidden in a document because the entire input surface was attacker-controllable language. The external communication channel was the agent's ability to send an email to any address, which delivered the one-time code to the attacker. The sensitive action was rebinding the recovery email and triggering the password reset.
Three capabilities: chat, email, and account resets. One agent. That is the whole attack chain.
When a probabilistic model holds privileged write access to account-management functions, and there is no deterministic gate in front of those functions, you have recreated a very old vulnerability in a new substrate. Researchers analyzing the incident pointed to the confused deputy pattern, a privilege-escalation class first documented by Norm Hardy in 1988, in which a program with legitimate authority is tricked by a less-privileged caller into misusing it.
What makes this worse than a classic confused deputy is that the deputy here was a probabilistic language model rather than a deterministic application, so the comforting assumption that the same input yields the same checked behavior does not hold.

OWASP files this under LLM06:2025, Excessive Agency, which describes an LLM granted enough capability or autonomy to take consequential actions without a human confirmation loop or a hard authorization boundary. Meta patched the issue quickly, and the fast fix is to their credit.
The general public framing, that an external party could request reset emails, is technically accurate. The more useful way to frame it is that the agent had quietly become the authorization surface, and no organization wants a probabilistic model sitting in that role. Whether the final root cause lands on the AI assistant or a connected reset flow, the defensive principle is the same:
Agents should not combine external access, excessive capabilities, or sensitive data and untrusted input. Opsin’s Agent Defense detects and prevents this from happening. It’s important to note that this is not a lapse in competence, and it is a trap that any team moving fast on AI can walk into.
This is the part worth sitting for, because the Meta agent case is not an outlier architecture. It is the default shape of the agents your own teams are building.
Consider what is already in production across most enterprises. Microsoft Copilot operates with the inherited permissions of the invoking user, which means a SharePoint permission inherited from a legacy site can surface in a Copilot response that an employee never expected to see. That is data oversharing, and it happens without anyone writing a malicious prompt.
One Opsin customer, Culligan, found sensitive data appeared in roughly 80 percent of a sample of Copilot queries before remediation, and reduced that to under 15 percent once the underlying access context was corrected. The exposure was real, already live, and invisible to tools built to watch network egress and file movement.
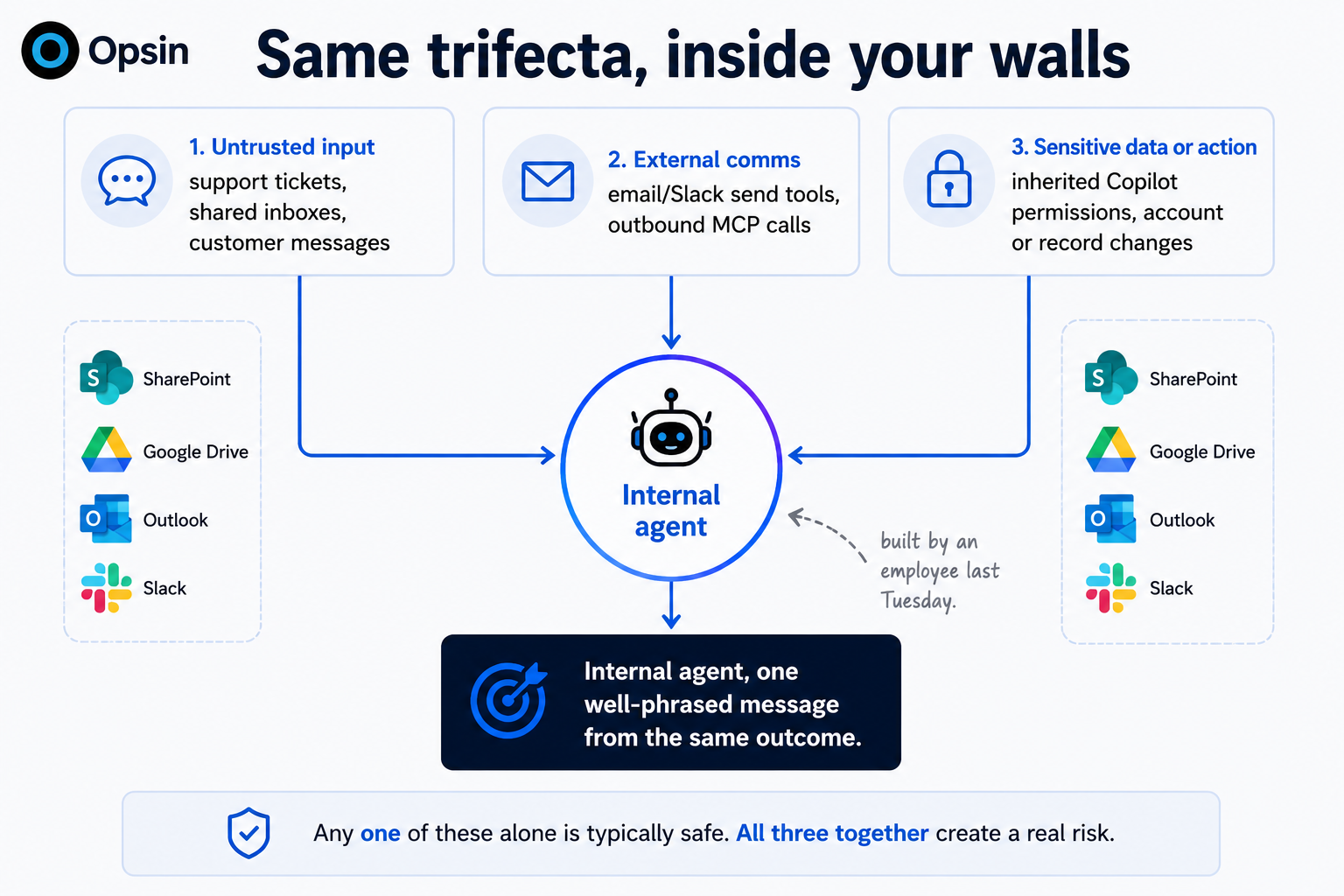
Now let’s add agency. Employees are building agents on top of ChatGPT Enterprise, Claude Enterprise, and Copilot that read support tickets or shared inboxes, which are textbook untrusted content, and then take actions and send messages outward. Many reach external systems through MCP, the Model Context Protocol, an open standard that lets an agent discover and call tools across services through a common interface.
MCP is genuinely useful, but it is also a trifecta accelerator, because a single agent can mix a tool that reads private data, a tool that ingests untrusted content, and a tool that can exfiltrate, with nothing in the protocol forcing those three to stay separate - the protocol is on the tool level, not the agent level. The agent inherits permissions no one meant for it to reasonably have when mixing the tools, operates as a non-human identity that most IAM programs do not yet inventory, and multiplies as agent sprawl outpaces the security team's ability to track what exists. Enterprise AI is the new endpoint, and most organizations have no asset list for it.
You cannot remediate what you cannot see, and the trifecta is a property of an agent's configuration rather than of any single request. You detect it by inspecting the wiring: which data and actions an agent can reach, what untrusted input it consumes, and whether it has an outbound path. That inspection is what Opsin's Agent Defense module provides, and the proactive risk assessment performs. We deploy in one click via API, simulate the kinds of queries real users and agents would actually issue, and surface AI risk within 24 hours instead of waiting for an incident to teach the lesson.
Underneath is a dynamic contextual layer that connects identity, data, and model behavior, so the assessment reflects what a user or agent can actually do rather than what a policy says it should.
Opsin’s AI Agent Defense is designed to catch configurations like Meta’s, identifying the Lethal Trifecta before an agent ever goes live.
An agent consuming untrusted input from an open chat surface, holding a sensitive action in the form of a password reset, and able to communicate externally through a send-email tool. Surfacing that finding lets a team remediate at the root cause, by removing a capability, scoping a tool, or inserting an out-of-band verification step, rather than triaging alerts after the agent is already taking instructions from strangers.
This sits at a different layer than the controls most teams reach for first. DLP-rooted platforms such as Microsoft Purview and Varonis treat AI as another data channel to watch, which catches some oversharing but says little about an agent's agency or its untrusted input surface. Prompt-layer tools inspect individual prompts and responses, which misses the structural fact that the danger lies in the combination of capabilities, not in any one message. Opsin works at the contextual layer that ties identity, data, and model behavior together, because that is where the trifecta becomes visible.
Meta's assistant has been patched, although other, non-AI related bypasses are still for sale on Telegram. If you’re specifically worried about account takeover on Instagram, follow the guidelines from Meta’s security team and implement some basic security hygiene. Turn on MFA, use a password manager, and check your accounts for suspicious activity.
The structural lesson has not gone anywhere, and it was never really about Meta. Any agent given a sensitive action, an untrusted input channel, and an outbound path is one well-phrased message away from the same outcome, and the question for the rest of us is no longer whether such agents exist in our environments. It is whether anyone has looked at the wiring before the next clip circulates with an internal tool in it.
Over the weekend, attackers opened a support chat with Meta's AI assistant, asked it to add a new email address to Barack Obama and other high profile Instagram accounts they did not own, waited for the one-time code to land in that inbox, read the code back to the assistant, then clicked the reset-password button the assistant offered, taking over the handle.
That sequence is a clear example of the Lethal Trifecta, and it happens to almost any organization deploying AI agents today. Reporting tied the technique to takeovers of high-profile handles, including the Obama-era White House account and the U.S. Space Force's chief master sergeant.
While the media narrative focuses on Meta because of the famous targets, that frame obscures the reality: this vulnerability is widespread. It is far more useful to view this as a common architectural trap that any organization, including yours, can easily fall into.
Look at the individual steps in the sequence: adding an email, sending a code, and triggering a reset. Each one did exactly what it was programmed to do. Together, however, they form what security engineer Simon Willison named the lethal trifecta, the combination of access to sensitive data or actions, exposure to untrusted input, and the ability to communicate externally. The trifecta rarely arrives as one bad call. It assembles itself out of sensible ones, which is exactly why it is so easy to ship and so hard to notice.
Willison’s original framing centered on data exfiltration through prompt injection, a class of attack OWASP ranks as LLM01:2025 in its Top 10 for LLM Applications, where the text the model ingests gets interpreted as instructions rather than data.
The Meta Instagram case generalizes the third pillar slightly: the agent did not just leak data, it executed a sensitive action. Nonetheless, the lethal trifecta still holds
Let’s map the three pillars onto what happened. The untrusted input was the support chat itself, a channel open to anyone with a target's username, so there was no need for a clever payload hidden in a document because the entire input surface was attacker-controllable language. The external communication channel was the agent's ability to send an email to any address, which delivered the one-time code to the attacker. The sensitive action was rebinding the recovery email and triggering the password reset.
Three capabilities: chat, email, and account resets. One agent. That is the whole attack chain.
When a probabilistic model holds privileged write access to account-management functions, and there is no deterministic gate in front of those functions, you have recreated a very old vulnerability in a new substrate. Researchers analyzing the incident pointed to the confused deputy pattern, a privilege-escalation class first documented by Norm Hardy in 1988, in which a program with legitimate authority is tricked by a less-privileged caller into misusing it.
What makes this worse than a classic confused deputy is that the deputy here was a probabilistic language model rather than a deterministic application, so the comforting assumption that the same input yields the same checked behavior does not hold.
OWASP files this under LLM06:2025, Excessive Agency, which describes an LLM granted enough capability or autonomy to take consequential actions without a human confirmation loop or a hard authorization boundary. Meta patched the issue quickly, and the fast fix is to their credit.
The general public framing, that an external party could request reset emails, is technically accurate. The more useful way to frame it is that the agent had quietly become the authorization surface, and no organization wants a probabilistic model sitting in that role. Whether the final root cause lands on the AI assistant or a connected reset flow, the defensive principle is the same:
Agents should not combine external access, excessive capabilities, or sensitive data and untrusted input. Opsin’s Agent Defense detects and prevents this from happening. It’s important to note that this is not a lapse in competence, and it is a trap that any team moving fast on AI can walk into.
This is the part worth sitting for, because the Meta agent case is not an outlier architecture. It is the default shape of the agents your own teams are building.
Consider what is already in production across most enterprises. Microsoft Copilot operates with the inherited permissions of the invoking user, which means a SharePoint permission inherited from a legacy site can surface in a Copilot response that an employee never expected to see. That is data oversharing, and it happens without anyone writing a malicious prompt.
One Opsin customer, Culligan, found sensitive data appeared in roughly 80 percent of a sample of Copilot queries before remediation, and reduced that to under 15 percent once the underlying access context was corrected. The exposure was real, already live, and invisible to tools built to watch network egress and file movement.
Now let’s add agency. Employees are building agents on top of ChatGPT Enterprise, Claude Enterprise, and Copilot that read support tickets or shared inboxes, which are textbook untrusted content, and then take actions and send messages outward. Many reach external systems through MCP, the Model Context Protocol, an open standard that lets an agent discover and call tools across services through a common interface.
MCP is genuinely useful, but it is also a trifecta accelerator, because a single agent can mix a tool that reads private data, a tool that ingests untrusted content, and a tool that can exfiltrate, with nothing in the protocol forcing those three to stay separate - the protocol is on the tool level, not the agent level. The agent inherits permissions no one meant for it to reasonably have when mixing the tools, operates as a non-human identity that most IAM programs do not yet inventory, and multiplies as agent sprawl outpaces the security team's ability to track what exists. Enterprise AI is the new endpoint, and most organizations have no asset list for it.
You cannot remediate what you cannot see, and the trifecta is a property of an agent's configuration rather than of any single request. You detect it by inspecting the wiring: which data and actions an agent can reach, what untrusted input it consumes, and whether it has an outbound path. That inspection is what Opsin's Agent Defense module provides, and the proactive risk assessment performs. We deploy in one click via API, simulate the kinds of queries real users and agents would actually issue, and surface AI risk within 24 hours instead of waiting for an incident to teach the lesson.
Underneath is a dynamic contextual layer that connects identity, data, and model behavior, so the assessment reflects what a user or agent can actually do rather than what a policy says it should.
Opsin’s AI Agent Defense is designed to catch configurations like Meta’s, identifying the Lethal Trifecta before an agent ever goes live.
An agent consuming untrusted input from an open chat surface, holding a sensitive action in the form of a password reset, and able to communicate externally through a send-email tool. Surfacing that finding lets a team remediate at the root cause, by removing a capability, scoping a tool, or inserting an out-of-band verification step, rather than triaging alerts after the agent is already taking instructions from strangers.
This sits at a different layer than the controls most teams reach for first. DLP-rooted platforms such as Microsoft Purview and Varonis treat AI as another data channel to watch, which catches some oversharing but says little about an agent's agency or its untrusted input surface. Prompt-layer tools inspect individual prompts and responses, which misses the structural fact that the danger lies in the combination of capabilities, not in any one message. Opsin works at the contextual layer that ties identity, data, and model behavior together, because that is where the trifecta becomes visible.
Meta's assistant has been patched, although other, non-AI related bypasses are still for sale on Telegram. If you’re specifically worried about account takeover on Instagram, follow the guidelines from Meta’s security team and implement some basic security hygiene. Turn on MFA, use a password manager, and check your accounts for suspicious activity.
The structural lesson has not gone anywhere, and it was never really about Meta. Any agent given a sensitive action, an untrusted input channel, and an outbound path is one well-phrased message away from the same outcome, and the question for the rest of us is no longer whether such agents exist in our environments. It is whether anyone has looked at the wiring before the next clip circulates with an internal tool in it.



.png)