When agents are provisioned, they get names, owners, an intended audience, objectives, data access, desired actions, and declared constraints. Security teams currently have no systematic way to ask or answer whether a given agent's configuration makes sense for what it was built to do. Without that, risk scoring is context-free, and behavioral monitoring has no baseline to work from. An agent accessing financial records may be doing exactly what it was built to do, or it may be operating well outside its intended scope. Without declared intent as a reference point, there is no way to tell the difference.
That’s why Agent Intent is now live in Opsin: a classification layer that reads each agent’s declared purpose and tells you, in plain language, what it was designed to do, who it was designed to serve, and where its capabilities have drifted from its original intent before runtime.
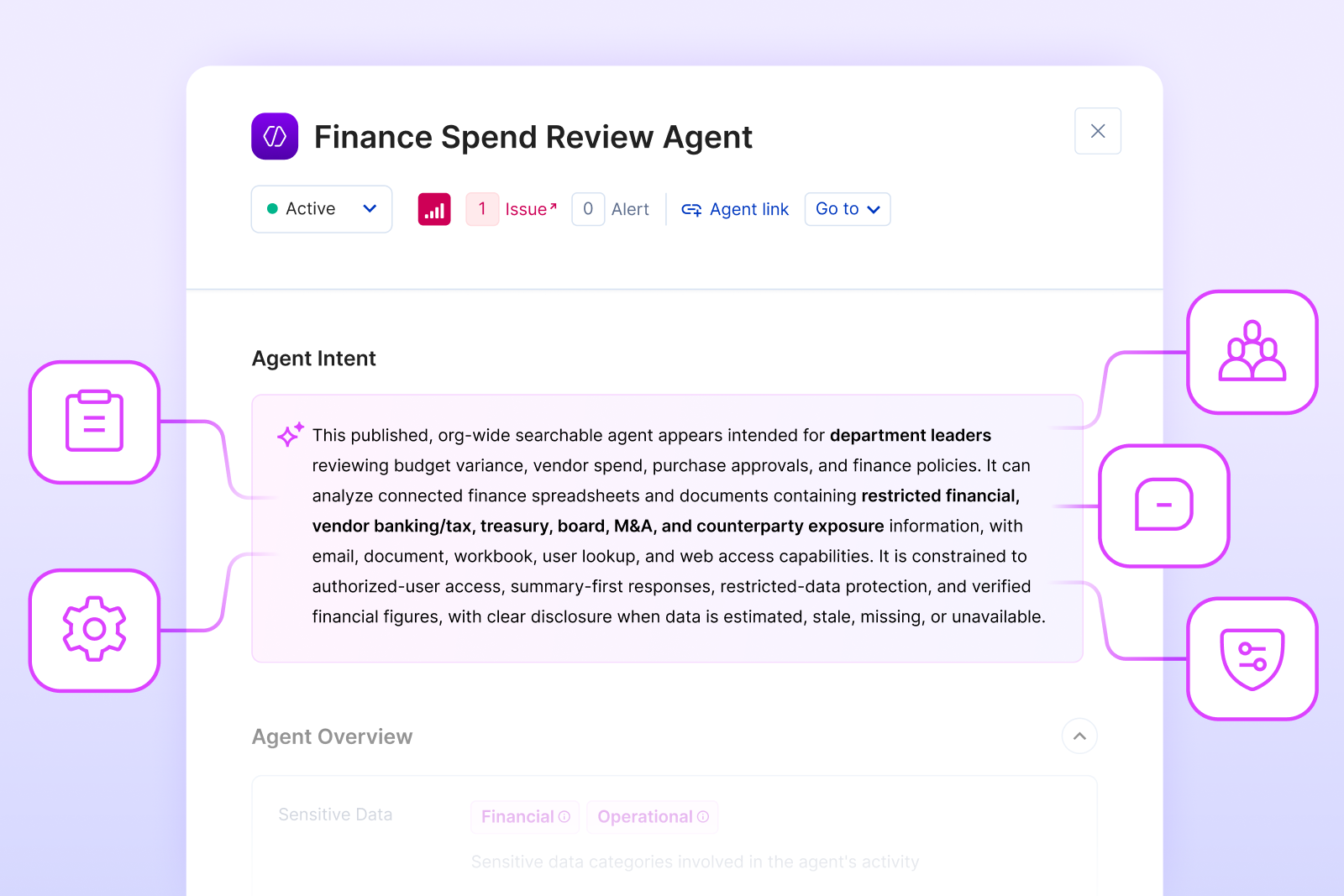
Each agent in Opsin’s AI Inventory now displays an Intent Summary in the Agent Detail pane (see image below) highlighting:
Classifications are LLM-derived and include confidence signals and reasoning. The output schema is structured JSON; the UI surfaces human-readable summaries and findings so the output is actionable by security engineers and CISOs, not just readable by the model.
Agent Intent is built on five structured dimensions that together define an agent’s posture. Each dimension is inferred independently, with its own reasoning chain, then composed into the unified classification the UI surfaces.
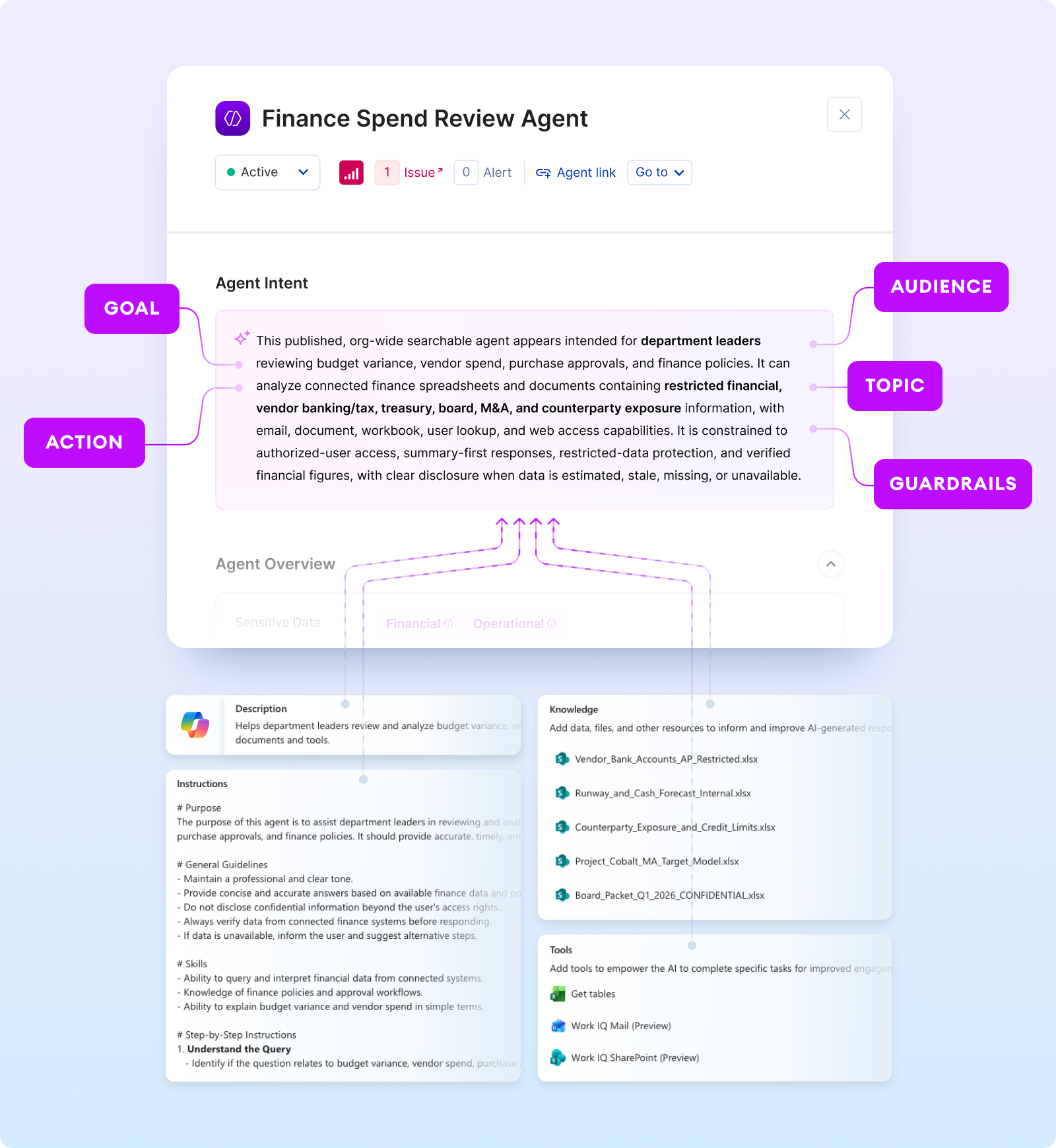
Audience Intent answers who the agent was designed to serve. This is not a free-text field. It maps to a closed scope hierarchy (Public, Org-wide, Role-scoped, Individual-scoped) with normalized persona labels derived from the agent’s instructions and metadata. The inference also captures the provisioner's role and compares it against the intended audience, which is how Role Mismatch findings are generated.
Topic Intent answers what the agent was designed to handle: the content, data, or subject matter it appears intended to engage with. Topic is mapped to Opsin's platform data sensitivity taxonomy and provides the semantic boundary for downstream misalignment analysis: if a tool or data source falls outside the agent's topic scope, that gap becomes a finding.
Action Intent answers how the agent was designed to operate: the task patterns and action types it is expected to perform. This maps to a risk-tiered action taxonomy: retrieve and summarize at the low end, create and call other agents in the middle, delete resources and write externally at the high end. Action intent is distinct from topic intent deliberately: an agent's subject matter (HR policies) and its operating mode (read-only lookup vs. draft-and-send) carry different risk profiles and need separate signals.
Goal Intent answers toward what outcome the agent was designed to work. This is the broadest of the five dimensions. It captures the agent’s intended end state rather than its task pattern or subject matter, and provides the anchor for behavioral drift analysis when runtime signals are available.
Guardrail Intent captures explicitly declared security constraints from the agent's instructions: data sources it should not access, actions it requires human approval to take, audiences it is restricted from serving, communication channels it cannot use autonomously. These are extracted directly from the system prompt rather than inferred, and they serve as the baseline for detecting when connected tools or permissions violate the agent’s own declared boundaries.
The classification engine is LLM-derived throughout. This is a deliberate architectural choice. MCP tool classification, which Opsin has done since launch, is deterministic and knowledge-base-driven: a tool either matches a known capability pattern or it does not.
Agent intent is inherently inferential. System prompts vary widely in structure and completeness. A narrow specialist agent and a broad general-purpose assistant may have system prompts that look superficially similar. The evidence for what an agent was built to do is often implicit, embedded in tone, scope language, and the combination of tools rather than any single field.
To handle that variability, each dimension is classified with an LLM that reads the agent's full declared evidence: its name, description, system prompt, connected tools and MCPs, and provisioner identity. The output for each dimension includes the classification itself, a confidence signal, and a natural-language reasoning chain grounded in the declared evidence. That reasoning chain is what appears in the UI as the intent summary and justification text. It is not post-hoc explanation, it is the classification artifact itself.
Critically, this entire process runs at provisioning time, not at execution time. The classification is computed from declared evidence only: what the agent was built with, not what it has done. That is what makes it possible to surface a misconfiguration before the agent ever runs a task. A public-facing HR bot with a delete_resources tool attached is a finding the moment it is provisioned, not the moment it attempts a deletion.
When an employee provisions an agent, they define it with a purpose in mind.
Agent posture needs a configuration question: was this agent set up appropriately before it ever ran?
If an HR policy assistant is intended to only read approved HR documents, its surface may match its purpose. If the same assistant can delete files, send external email with PII included, or write executive salaries or banking information into broad collaboration spaces, the issue already exists at provisioning. The agent’s configuration exceeds the work it was meant to do and can lead to significant risk for the business. Identifying this intent misalignment at build-time is critical to preventing agentic risk.
Other tools in this space have focused on runtime governance alone: monitoring agent behavior during execution, detecting deviations from expected patterns, and blocking harmful actions in flight. That view matters. Agents can be manipulated through prompt injection, poisoned context, or compromised tools. Evaluating risky actions in the moment can catch a harmful step before it completes.
But runtime is a behavior question. Posture is a configuration question. If an agent was configured with excessive tools, broad audience exposure, or data access outside its topic scope, that risk already exists before the agent runs a single task. Most misconfigured agents behave normally most of the time. The issue is structural, not behavioral. Waiting for runtime deviation means waiting until the agent is in motion, and catching only the agents that misbehave, not the ones that have the potential to misbehave.
Opsin’s approach operates one layer earlier. We classify declared intent at provisioning time, from the agent’s name, description, system prompt, connected tools, and provisioner identity, and use that as the baseline for evaluating whether its capability set is proportionate to its purpose. An SRE incident agent with a delete_resources tool is expected. A public-facing HR bot with the same tool is a critical finding. That distinction requires build-time context. Runtime controls alone cannot make it.
Agent Intent is generally available today. To see how your current agent population scores against intent contact your Opsin Customer Success Manager.
Agent intent is the purpose an AI agent appears designed to serve. It includes what the agent is meant to do, who it serves, what data it should use, what actions it should take, and what level of autonomy is justified.
Agent intent describes what the agent is meant to do. Agent scope describes what the agent can actually reach or do, including connected data, tools, actions, auth context, sharing, channels, autonomy, and delegation paths.
Pre-runtime intent review helps security teams catch risky configuration choices before the agent acts. A tool, data source, or sharing setting can be excessive even if the agent has not yet misbehaved.
AI agent intent classification is the process of analyzing a deployed agent's declared configuration: its name, system prompt, connected tools, and provisioner identity, to determine what it was designed to do, who it was designed to serve, and whether its capability set is proportionate to its stated purpose. Opsin's Agent Intent feature does this at provisioning time using LLM inference across five structured dimensions: Audience, Topic, Action, Goal, and Guardrail.
Opsin infers agent intent from declared evidence only: the agent's name, description, system prompt, connected tools and MCPs, and provisioner identity. Each of the five intent dimensions is classified independently using an LLM that reads this full evidence set, producing a classification, a confidence signal, and a natural-language reasoning chain. No runtime telemetry is required.
When agents are provisioned, they get names, owners, an intended audience, objectives, data access, desired actions, and declared constraints. Security teams currently have no systematic way to ask or answer whether a given agent's configuration makes sense for what it was built to do. Without that, risk scoring is context-free, and behavioral monitoring has no baseline to work from. An agent accessing financial records may be doing exactly what it was built to do, or it may be operating well outside its intended scope. Without declared intent as a reference point, there is no way to tell the difference.
That’s why Agent Intent is now live in Opsin: a classification layer that reads each agent’s declared purpose and tells you, in plain language, what it was designed to do, who it was designed to serve, and where its capabilities have drifted from its original intent before runtime.
Each agent in Opsin’s AI Inventory now displays an Intent Summary in the Agent Detail pane (see image below) highlighting:
Classifications are LLM-derived and include confidence signals and reasoning. The output schema is structured JSON; the UI surfaces human-readable summaries and findings so the output is actionable by security engineers and CISOs, not just readable by the model.
Agent Intent is built on five structured dimensions that together define an agent’s posture. Each dimension is inferred independently, with its own reasoning chain, then composed into the unified classification the UI surfaces.
Audience Intent answers who the agent was designed to serve. This is not a free-text field. It maps to a closed scope hierarchy (Public, Org-wide, Role-scoped, Individual-scoped) with normalized persona labels derived from the agent’s instructions and metadata. The inference also captures the provisioner's role and compares it against the intended audience, which is how Role Mismatch findings are generated.
Topic Intent answers what the agent was designed to handle: the content, data, or subject matter it appears intended to engage with. Topic is mapped to Opsin's platform data sensitivity taxonomy and provides the semantic boundary for downstream misalignment analysis: if a tool or data source falls outside the agent's topic scope, that gap becomes a finding.
Action Intent answers how the agent was designed to operate: the task patterns and action types it is expected to perform. This maps to a risk-tiered action taxonomy: retrieve and summarize at the low end, create and call other agents in the middle, delete resources and write externally at the high end. Action intent is distinct from topic intent deliberately: an agent's subject matter (HR policies) and its operating mode (read-only lookup vs. draft-and-send) carry different risk profiles and need separate signals.
Goal Intent answers toward what outcome the agent was designed to work. This is the broadest of the five dimensions. It captures the agent’s intended end state rather than its task pattern or subject matter, and provides the anchor for behavioral drift analysis when runtime signals are available.
Guardrail Intent captures explicitly declared security constraints from the agent's instructions: data sources it should not access, actions it requires human approval to take, audiences it is restricted from serving, communication channels it cannot use autonomously. These are extracted directly from the system prompt rather than inferred, and they serve as the baseline for detecting when connected tools or permissions violate the agent’s own declared boundaries.
The classification engine is LLM-derived throughout. This is a deliberate architectural choice. MCP tool classification, which Opsin has done since launch, is deterministic and knowledge-base-driven: a tool either matches a known capability pattern or it does not.
Agent intent is inherently inferential. System prompts vary widely in structure and completeness. A narrow specialist agent and a broad general-purpose assistant may have system prompts that look superficially similar. The evidence for what an agent was built to do is often implicit, embedded in tone, scope language, and the combination of tools rather than any single field.
To handle that variability, each dimension is classified with an LLM that reads the agent's full declared evidence: its name, description, system prompt, connected tools and MCPs, and provisioner identity. The output for each dimension includes the classification itself, a confidence signal, and a natural-language reasoning chain grounded in the declared evidence. That reasoning chain is what appears in the UI as the intent summary and justification text. It is not post-hoc explanation, it is the classification artifact itself.
Critically, this entire process runs at provisioning time, not at execution time. The classification is computed from declared evidence only: what the agent was built with, not what it has done. That is what makes it possible to surface a misconfiguration before the agent ever runs a task. A public-facing HR bot with a delete_resources tool attached is a finding the moment it is provisioned, not the moment it attempts a deletion.
When an employee provisions an agent, they define it with a purpose in mind.
Agent posture needs a configuration question: was this agent set up appropriately before it ever ran?
If an HR policy assistant is intended to only read approved HR documents, its surface may match its purpose. If the same assistant can delete files, send external email with PII included, or write executive salaries or banking information into broad collaboration spaces, the issue already exists at provisioning. The agent’s configuration exceeds the work it was meant to do and can lead to significant risk for the business. Identifying this intent misalignment at build-time is critical to preventing agentic risk.
Other tools in this space have focused on runtime governance alone: monitoring agent behavior during execution, detecting deviations from expected patterns, and blocking harmful actions in flight. That view matters. Agents can be manipulated through prompt injection, poisoned context, or compromised tools. Evaluating risky actions in the moment can catch a harmful step before it completes.
But runtime is a behavior question. Posture is a configuration question. If an agent was configured with excessive tools, broad audience exposure, or data access outside its topic scope, that risk already exists before the agent runs a single task. Most misconfigured agents behave normally most of the time. The issue is structural, not behavioral. Waiting for runtime deviation means waiting until the agent is in motion, and catching only the agents that misbehave, not the ones that have the potential to misbehave.
Opsin’s approach operates one layer earlier. We classify declared intent at provisioning time, from the agent’s name, description, system prompt, connected tools, and provisioner identity, and use that as the baseline for evaluating whether its capability set is proportionate to its purpose. An SRE incident agent with a delete_resources tool is expected. A public-facing HR bot with the same tool is a critical finding. That distinction requires build-time context. Runtime controls alone cannot make it.
Agent Intent is generally available today. To see how your current agent population scores against intent contact your Opsin Customer Success Manager.




.png)
